Exploring Apache Lucene - Part 1: The Index
Tech Blog
January 16, 2023 • ☕️☕️ 9 min read
When I joined Yelp in 2020, as a software engineer, I became part of the Ranking Platform team. The team is responsible for the development and maintenance of Yelp’s search and ranking infrastructure, a crucial part of our ecosystem, that allows for business search, reviews search and powers the internal real-time ad bidding system. At that time, I was part of an initiative to revamp our core search & ranking infra in terms of performance and cost efficiency. This effort resulted in an open-source project - nrtsearch - which, as of early 2023, is used for the majority of search and ranking use cases at Yelp, with more migrations underway set to replace Elasticsearch. With nrtsearch our p50s, p95s and p99s improved by 30-50% while costs dropped by as much as 40% in some cases. You can read more about the nrtsearch project results in the blog post from Yelp’s Engineering Blog:
Nrtsearch: Yelp’s Fast, Scalable and Cost Effective Search Engine
Nrtsearch development was led by senior folks, industry experts who know ins and outs of Apache Lucene - the core search library on top of which nrtsearch was built. I worked on well-scoped projects, like scalable ingestion, logging, plugin development and scatter-gather service, which allows for application-level cluster sharding. While I enjoyed those projects, I feel that, for a long time, I treated the nrtsearch core search functionality as a black-box - not fully understanding its internals. Therefore, I decided to take a step back, explore, and understand Apache Lucene - a search library at the core of nrtsearch and Elasticsearch (Elastic - a company built around Elasticsearch has a market cap of 5B$).
This is the first tech blog post from the series Exploring Apache Lucene in which I’ll describe, in the bottom-up manner, the building blocks of modern search engines.
Lucene’s jargon
Before starting, I want to explain some terms closely linked to Apache Lucene. They don’t necessarily map 1:1 to other DB technologies, what is at times confusing when reading Lucene’s docs and related blog posts.
- document - a record, the unit of search and index, a set of fields. Documents are added to a Lucene index, and can be retrieved by a search query.
- field - a typed slot in a document. A field is a sequence of terms. Document can have multiple fields.
- term - a value from the source document, the unit of search. Used for building the inverted index
- index - a collection of documents, typically with the same schema.
- inverted index - an internal data structure that maps terms to documents by ID, efficient for text-search queries.
- stored fields - an array of all field values per field, in document order, stored in index in non-inverted manner. Efficient for getting many field values for a few docs.
- doc values - Lucene’s column-stride field value storage. Efficient for getting a few field values for many docs. Useful for sorting and faceting.
- index segments - Lucene indexes may be composed of multiple sub-indexes, or segments. Each segment is a fully independent index, which could be searched separately.
Representing data with Lucene
Inverted Index
Inverted index is a data structure that maps terms (i.e. words or phrases) to the documents that contain them. The index is built by analyzing the text of the documents and extracting terms from them. The inverted index allows for fast and efficient searching by providing a way to look up documents that contain a specific term or set of terms. It also provides a way to rank the relevance of the search results by determining how many of the search terms match to a specific document.
The inverted index is composed of two substructures:
- term dictionary - groups all the terms included in the documents in a sorted list.
- postings list - creates a list of each term, indicating the documents where the term appears.
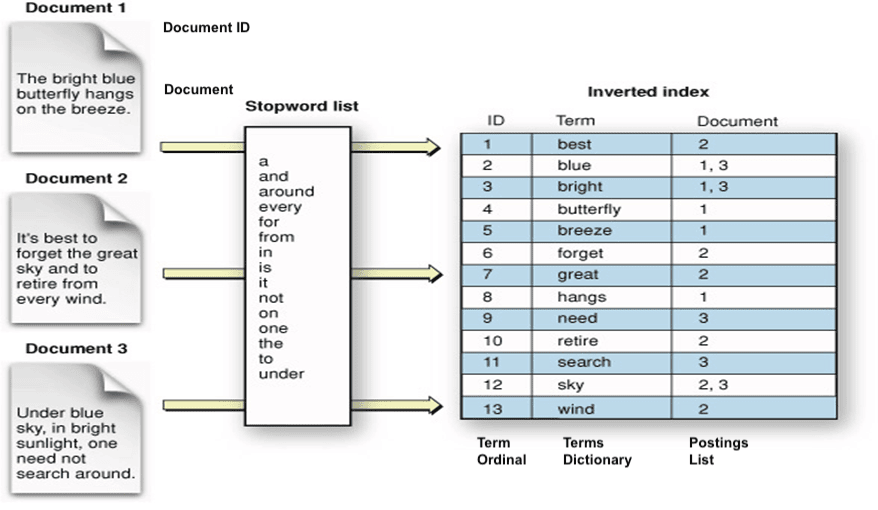
In the above example we can see three documents indexed into Lucene’s inverted index. Each of the document’s conten is analyzed (tokenized) into terms which are inserted into inverted index.
Since the terms in the dictionary are sorted, we can quickly find a term (think binary search), and subsequently its occurrences in the postings-structure. This is contrary to a “forward index”, which lists terms related to a specific document.
DocValues
Inverted index builds a mapping of terms found in all the documents in the index to a list of documents that the term appears in. This makes search very fast - since users search by terms, having a ready list of term-to-document values makes the query process faster.
For other features that are associated with search, such as sorting, faceting, and highlighting, this approach is not very efficient. The faceting engine, for example, must look up each term that appears in each document that will make up the result set and pull the document IDs to build the facet list.
DocValue fields are column-oriented fields with a document-to-value mapping built at index time - an uninverted (forward) index. This approach can make lookups for faceting, sorting, and grouping much faster, as we can retrieve fields for multiple docs with the single disk seek (utilizing the filesystem cache).
DocValues should be preferred over “stored fields” unless the complete document is being retrieved by a query.
Stored Fields
Similar to DocValues, Stored fields have been created to effectively persist values (differently to how inverted index does it) of the document fields, and then, retrieve them when needed.
Stored fields are organised in a row manner. This means that, given a set of fields, for each document, the values of these fields are concatenated in a row. The rows are then stored sequentially on disk according to their Lucene doc id. Each row may have a different size depending on the number of fields defined for that document and data types (e.g. string or text fields have variable sizes). The pointers to each row are stored for allowing fast access to them.
This technique is particularly useful if our search query needs to return complete documents (with all their fields) rather than just a few fields.
DocValues and Stored fields approached are not mutually exclusive settings, a given field, apart from being indexed into the inverted index, can have DocValues and Stored fields enabled. The queries that will be run against the index should determine which of these approaches is used. It’s important to keep in mind that both of approached are effectively duplicating data and storing them in a format suitable for specific the access pattern - so enabling both may result in a bloated index size.
Insertions
When building inverted indexes, we need to prioritize things like: search speed, index compactness, indexing speed and the time it takes for new changes to become visible. Search speed and index compactness are related: when searching over a smaller index, less data needs to be processed, and more of it will fit in memory. Both, particularly compactness, come at the cost of indexing speed.
To minimize index sizes, various compression techniques are used. For example, when storing the postings (which can get quite large), Lucene does tricks like delta-encoding - e.g. [1, 9, 420] is stored as [1, 8, 411] - so small numbers can be saved with less bytes.
When new documents are added, the index changes are first buffered in memory. Eventually, the index files in their entirety, are flushed to disk. The written files make up an index segment.
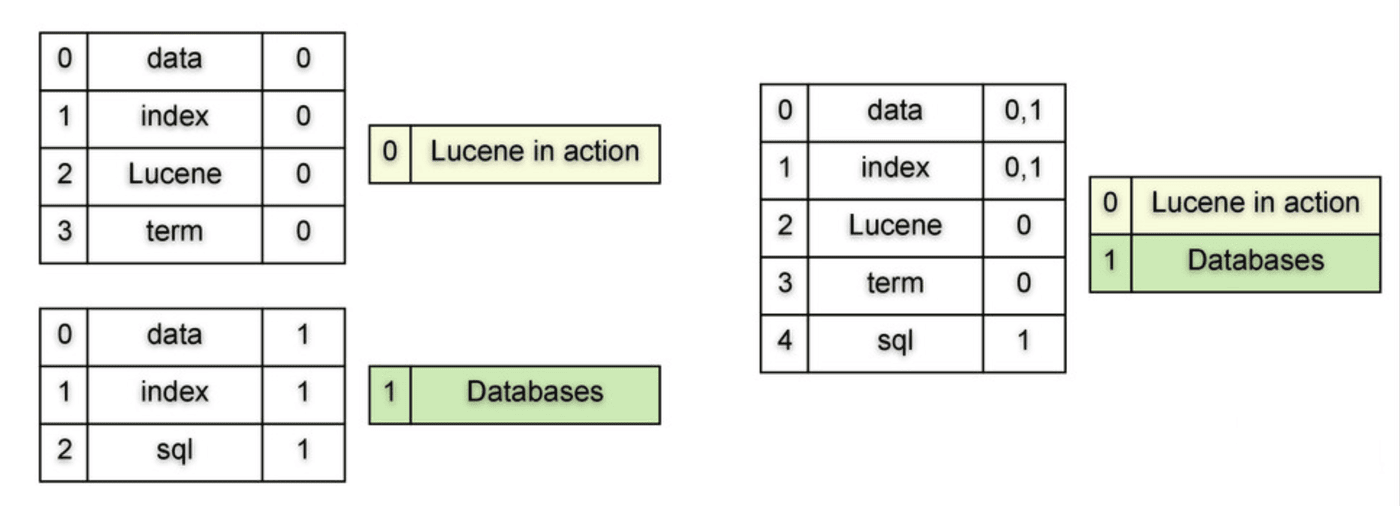
Lucene index segments are “write-once” files: once a segment has been written to permanent storage (to disk), it is never altered. This means that indexes are actually comprised of several files which are each subsets of the full index. To prevent eternal fragmentation of the index, segments are periodically merged. In the example above (source) we have two segments, each consisting of a single document. On the right side of the image, we can see a result of a segment merge - where 2 segments are merged to form a new segment.
Deletions
For each segment, Lucene maintains a per-segment bitset (vector of 0 and 1s). Flipping a bit from 1 to 0 signals to Lucene that a document is deleted. All subsequent searches simply skip any deleted documents. It is not until segments are merged that the bytes consumed by deleted documents are reclaimed, as after the merge the resulting segment won’t contain deleted documents. Deleting the documents in-place in the existing segment would be far too costly.
Updates
Updating a previously indexed document is a “cheap” delete followed by a re-insertion of the document. This means that updating a document is even more expensive than adding it in the first place. Thus, storing things like rapidly changing values in a Lucene index is probably not a good idea – there is no in-place update of values.
Visualising Lucene’s segment merges
Below there is a visualisation of how Lucene handles insertions, deletion and segment merges (taken from this great blog post by Michael McCandless). Each segment is a bar, whose height is the size (in MB) of the segment. Segments on the left are the largest; as new segments are flushed, they appear on the right. The dark grey band on top of each segment shows the proportion of deletions in that segment.

Lucene’s data storage architecture: pros and cons
- (-) Document insertions require writing a new segment. Which can be costly for single-document insertions. Therefore bulk inserts are preferred.
- (+) Segments are never modified in-place, so they are filesystem cache-friendly. Segments can be searched concurrently lock-free, with no risk of race conditions. It also allows for concurrent query execution.
- (+) The inverted index allows for fast and efficient searching by providing a way to look up documents that contain a specific term or set of terms.
- (+) Terms compression. Deduplication of terms within a segment, it can save a lot of space for very high-frequency terms.
- (+) Terms are uniquely identified by an ordinal, useful for sorting and faceting.
- (+) DocValues optimization can help with efficient sorting and faceting. Stored fields can help with retrieving whole documents.
Exploring Lucene series is continued in Exploring Apache Lucene - Part 2: Search and Ranking and Exploring Apache Lucene - Part 3: Running at Scale.