Question Answering with LangChain, HuggingFace, and Elasticsearch
Tech Blog
May 22, 2024 • ☕️☕️ 10 min read
Let’s build a retrieval-augmented generation (RAG) pipeline powered by a LLM that can run locally in a notebook. We’ll use the content of this blog as our sample knowledge source. By leveraging langchain and HuggingFace’s transformers packages, I aim to keep the code minimal and utilize their elegant abstractions.
For our vector store, I’m using Elasticsearch Serverless (currently in open preview), which will enable semantic search on embedded textual data. You can run the RAG pipeline locally in your notebook, linked at the end of this post.
High-level architecture
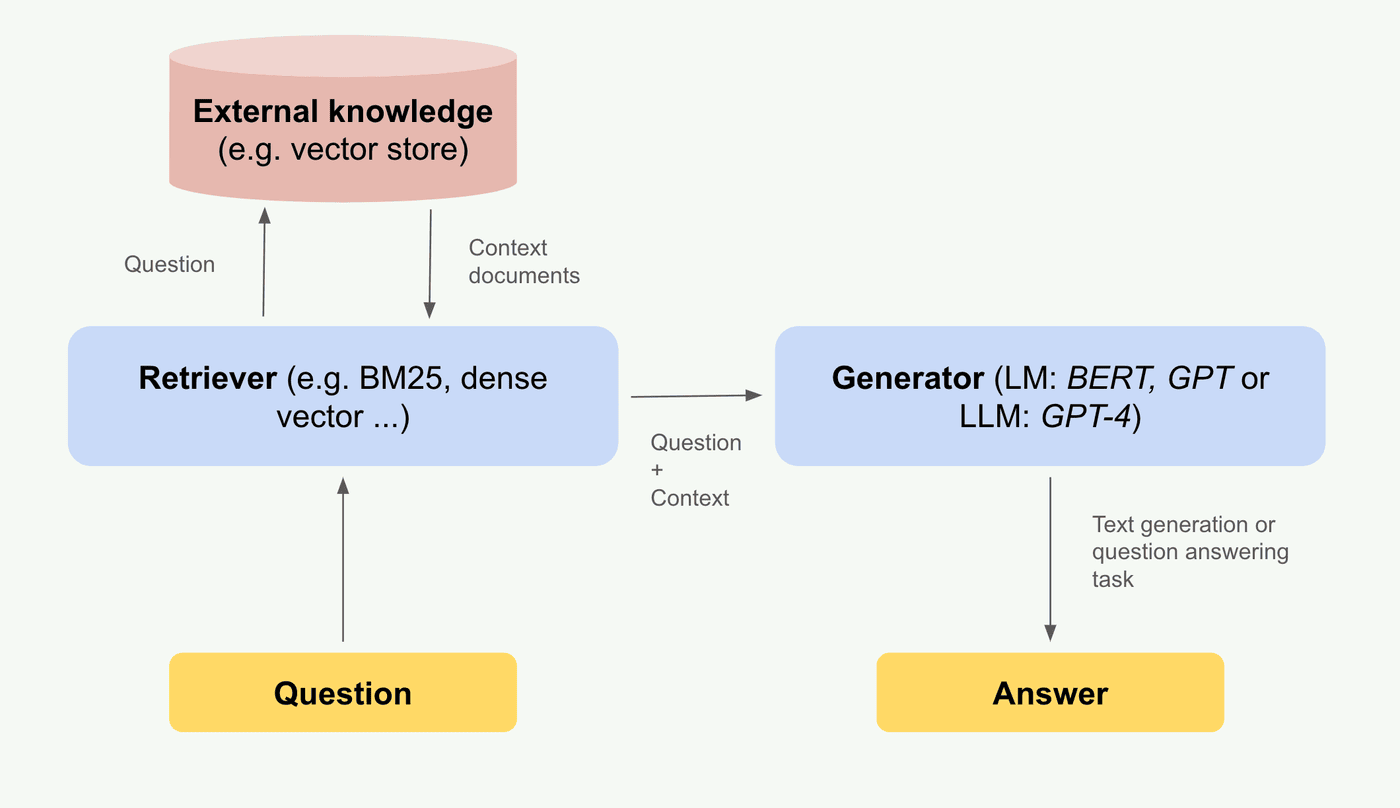
- Question: The user input question in natural language.
- Retriever: A search engine that retrieves relevant documents from the knowledge source and passes them as context to the generator.
- Knowledge Source: A repository of documents where their vector representations are stored, serving as the database for the retriever to search for answers.
- Generator: A language model that generates answers based on the question and the retrieved context.
- Answer: The generated answer to the user’s question in natural language.
Embeddings
We are using default HuggingFaceEmbeddings to encode documents into 768-dimensional dense vectors. These embeddings are generated using a pre-trained sentence-transformers/all-mpnet-base-v2 model.
from langchain_community.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings()Knowledge source
We are using the content of this blog as a knowledge source for our toy example.
Crawling blog content
I used the Elastic web crawler to crawl the blog content. Then, I scanned the Elasticsearch index and saved the _source of docs in a JSONL file: blog-pages.jsonl.
The JSONLoader is used to load documents from the file and extract metadata. The content_key specifies the key in the JSON record that contains the textual content of the document, which will be embedded as a vector for semantic search.
from langchain_community.document_loaders import JSONLoader
def metadata_func(record, metadata):
metadata["url"] = record.get("url")
metadata["title"] = record.get("title")
metadata["links"] = record.get("links")
metadata["meta_description"] = record.get("meta_description")
return metadata
loader = JSONLoader(
file_path='./blog-pages.jsonl',
jq_schema='.',
content_key="body_content",
metadata_func=metadata_func,
json_lines=True
)Document chunking
Language models have token limits, so chunking breaks down large documents into smaller, manageable pieces that fit within these limits. Larger chunks capture more context but may lead to inefficiency or truncation, while smaller chunks are better for technical or dense content.
When selecting chunk_size, choose a size within the model’s token limit. For chunk_overlap, select a value that preserves context across chunk boundaries.
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=512, chunk_overlap=64
)
docs = loader.load_and_split(text_splitter=text_splitter)Vector store - Elasticsearch Serverless
I’m ingesting embedded data into Elasticsearch Serverless, which will serve as our vector store. This service allows you to deploy and use Elastic without managing the underlying cluster, including nodes, data tiers, and scaling. Serverless instances are fully managed, autoscaled, and automatically upgraded by Elastic. It’s currently in technical preview and free to use.
ES_VECTOR_FIELD = 'content_embedding'
ES_INDEX_NAME = 'blog-search-qa'from langchain_elasticsearch import ElasticsearchStore
ElasticsearchStore.from_documents(
docs,
embeddings,
vector_query_field=ES_VECTOR_FIELD,
es_url=es_url,
index_name=ES_INDEX_NAME,
es_api_key=es_api_key
)Retrieval with vector search
A retriever is an interface that returns documents given an unstructured query. It is more general than a vector store. A retriever does not need to be able to store documents, only to return (or retrieve) them.
In our case, we are using pure vector search for retrieval. However, refer to the ElasticsearchRetriever documentation for examples on how to configure a retriever with BM25 or hybrid search.
In our kNN query, the k parameter specifies the number of nearest neighbors to retrieve. The num_candidates parameter defines the search space per shard, representing the initial pool of candidates from which the most relevant k neighbors are selected.
from langchain_elasticsearch import ElasticsearchRetriever
def vector_query(search_query, k=3):
return {
"knn": {
"field": ES_VECTOR_FIELD,
"query_vector": embeddings.embed_query(search_query),
"k": k,
"num_candidates": 20,
}
}
retriever = ElasticsearchRetriever.from_es_params(
index_name=ES_INDEX_NAME,
body_func=vector_query,
content_field="text",
url=es_url,
api_key=es_api_key
)Question answering
Let’s use a pre-trained question-answering model to extract answers from a set of context documents. Using the transformers library, we initialize a question-answering pipeline with the distilbert/distilbert-base-cased-distilled-squad model. This model is an efficient and lightweight Transformer model trained by distilling BERT base, and it is fine-tuned on SQuAD specifically for question-answering tasks.
Hugging Face pipelines provide an easy way to use models for inference. These pipelines abstract most of the complex code from the library, offering a simple API dedicated to various tasks, such as question answering or text generation.
In our question-answering task, given a user query, the retriever fetches relevant documents from the knowledge source. The context from these documents is then passed to the question-answering model to generate an answer. See the example below:
from transformers import pipeline
import torch
qa_model = pipeline("question-answering", model="distilbert/distilbert-base-cased-distilled-squad", torch_dtype=torch.float32)question = "What is a good tyre width for bikepacking trips?"
print (f'Question: {question}\n')
context_docs = retriever.invoke(question)
context = " ".join([doc.page_content for doc in context_docs])
print(f'Using context from {len(context_docs)} blog pages to answer the question:\n')
for doc in context_docs:
page_title = doc.metadata.get("_source", {}).get("metadata", {}).get("title", {})
print(f'- {page_title}')
qa_response = qa_model(question = question, context = context)
print(f'\nAnswer: {qa_response["answer"]}')Output:
Question: What is a good tyre width for bikepacking trips?
Using context from 3 blog pages to answer the question:
- Bikepacking in France - Provence and Hautes-Alpes — Jedr's Blog
- Gravmageddon 2023: Karkonosze - Izery Gravel Race — Jedr's Blog
- Tuscany Trail: Bikepacking in Italy — Jedr's Blog
Answer: 45mmIn the retrieved context blog posts (retrieved using kNN vector search), I discuss my bikepacking setup and tire width. In fact, my gravel bike is equipped with 45mm tires! You can check the context of the blog posts yourself to see how the answer was generated:
- Bikepacking in France - Provence and Hautes-Alpes
- Gravmageddon 2023: Karkonosze - Izery Gravel Race
- Tuscany Trail: Bikepacking in Italy
Text generation with locally running LLM
We can also use a large language model to generate comprehensive answers to questions, much like ChatGPT. For this purpose, we can utilize the text-generation pipeline from HuggingFace. I used HuggingFaceH4/zephyr-7b-beta with “just” 7 billion parameters. You can test it yoursef with Zephyr Chat app.
Similar to the question-answering example, we can pass a question and context as the user prompt, and the model can generate an answer based on that. Here is an example code:
pipe = pipeline("text-generation", model="HuggingFaceH4/zephyr-7b-beta", torch_dtype=torch.bfloat16, device_map="auto")
# limit the number of context docs to retrieve to top 1 context doc for faster processing by LLM
retriever = ElasticsearchRetriever.from_es_params(
index_name=ES_INDEX_NAME,
body_func=lambda query: vector_query(query, k=1),
content_field="text",
url=es_url,
api_key=es_api_key
)question = "What is a good tyre width for bikepacking trips?"
context_docs = retriever.invoke(question)
context = " ".join([doc.page_content for doc in context_docs])
# We use the tokenizer's chat template to format each message - see https://huggingface.co/docs/transformers/main/en/chat_templating
messages = [
{
"role": "system",
"content": "You are a helpful question answering chatbot, that tries to answer the question given the context.",
},
{"role": "user", "content": f'Question: {question}, context: {context}\n'},
]
prompt = pipe.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])Output of RAG pipeline with LLM used for answer generation:
Based on the provided context, a good tire width for bikepacking trips would be around 45mm, as the author’s Canyon Grizl AL 6 bike is equipped with 45mm wide tires. This tire width provides a good balance between comfort, traction, and speed on various terrain types commonly encountered during bikepacking trips. However, tire choice ultimately depends on personal preference, the specific terrain being tackled, and the rider’s riding style. It’s always recommended to test different tire widths and tread patterns in training rides before embarking on a long bikepacking trip.
Below is the full system prompt, togerher with user prompt (question + context) and the generated answer. The fact that it’s all running locally is so cool!
<|system|>
You are a helpful question answering chatbot, that tries to answer the question given the context.</s>
<|user|>
Question: What is a good tyre width for bikepacking trips?, context: you feel like you've cycled to another planet when you reach this part of the ascent. Bikepacking Setup Bike The bike model is a Canyon Grizl AL 6 with 45mm wide tyres. Bags: 16.5L Ortlieb seatpack - I had all my camping gear and off-bike clothes there. You can fit some baguettes on top of it! 11L Ortlieb QR handlebar bag - I stored there my cycling clothes, warm and waterproof layers, and a camera in case of rain. 4.5L frame bag - I stored the bike repair kit and toothbrush, soap, etc. 2 x 5L fork bags - I was able to fit my tent and some random stuff there. The tent poles were strapped to a fork as well. 1L Apidura top tube bag - I love it for its magnetic rivets to quickly access important stuff. I kept my phone and documents there. 2 x 1L snack packs - One to hold the telephoto lens, the other to carry a bottle of wine when needed. Gear Camping Tent: Big Agnes Copper Spur HV UL2. At ~1400g with its packable size, this tent has been accompanying me on bikepacking trips for the past few years. Sleeping Bag: Cumulus 0°C comfort. It weighs 850g. It's a bit bulky, but I prefer to be a bit too warm rather than too cold at night. It fits well into the seat pack. Other camping gear: Stuff from Decathlon with a good price-to-weight ratio. Photo Fujifilm X-S10 (465g) Fujinon 18-55mm F/2.8-4 is not the sharpest lens, but at 310 g, it has a good performance-to-weight ratio. Fujinon 70-300mm F/4-5.6, my all-time favourite lens, has great sharpness and a decent focal length range at a weight of 580g. Actually, I like the fact that the lens is made out of quality plastic rather than metal because it makes it lighter. Mini-tripod for night shots: the ballhead taken from a regular tripod was the heaviest part. DIY 3-point camera strap compatible with peak design quick-release anchor links, tailored for cycling with a camera on my back. Chain Waxing and Bikepacking I've been waxing the chain on my road bike for almost a year, and
</s>
<|assistant|>
Based on the provided context, a good tire width for bikepacking trips would be around 45mm, as the author's Canyon Grizl AL 6 bike is equipped with 45mm wide tires. This tire width provides a good balance between comfort, traction, and speed on various terrain types commonly encountered during bikepacking trips. However, tire choice ultimately depends on personal preference, the specific terrain being tackled, and the rider's riding style. It's always recommended to test different tire widths and tread patterns in training rides before embarking on a long bikepacking trip.How can LLM run locally in a notebook?!
Apple Silicon features a unified memory architecture that shares memory between the CPU and GPU. This design allows both the CPU and GPU to access the same data without needing to copy it between separate memory pools. As a result, if the model fits within the available RAM, both the CPU and GPU can work efficiently without significant bottlenecks.
The required memory for our 7-billion-parameter model, HuggingFaceH4/zephyr-7b-beta, is about 14GB, which fits comfortably on my 32GB M2 Pro MacBook. With reasonably short prompts, it performs almost as fast as the ChatGPT app.
Out of curiosity, I explored what happens if the model does not fit in memory. I created three instances of our 7-billion-parameter model and, as expected, received a warning: Some parameters are on the meta device because they were offloaded to the disk. Offloading the model to disk made it unusably slow. I eventually gave up and restarted the kernel after waiting for a response that never came.
Notebook
All of the steps listed above are availabe in the Python notebook.