Exploring Apache Lucene - Part 3: Running at Scale
Tech Blog
September 16, 2023 • ☕️☕️ 11 min read
Let’s explore real-world solutions that enable us to deploy and operate Apache Lucene at scale and discuss the advantages that a stateless architecture offers when managing shifting traffic patterns.
If you are interested in Apache Lucene, I’m linking below other posts from the Exploring Apache Lucene series where I’m discussing its architecture in a bottom-up manner:
Lucene at scale
As search volumes and datasets grow, maintaining high performance with Apache Lucene can become increasingly challenging. As a result, scaling Lucene-based search engines becomes a crucial consideration for data-driven businesses. There are several open-source implementations that can help achieve this goal. I’m personally familiar with Elasticsearch and nrtSearch, and I will use them to talk about different architectures.
Both Elasticsearch and nrtSearch allow you to scale out Lucene across multiple nodes, with an added API wrapper for data ingestion and search. But their different designs and architectures make the problem of running Lucene at scale quite interesting. While they all aim to solve the same problem, their specific implementations have different tradeoffs in terms of performance, scalability, and ease of use.
Let’s start with discussing the foundations.
Data distribution
If your searches are starting to take longer or your index is getting too large for a node to handle, it might be time to consider distributing your data across multiple nodes.
To do this, you can divide your index into smaller partitions, called shards, which can then be distributed across separate nodes. A search engine can partition a search query into sub-searches that are run on each shard, and then the results are combined - this is known as Scatter-gather.
The underlying technical details of index sharding are typically invisible to end users. They’ll simply experience faster search performance, especially when working with very large indexes. By distributing your data, you can overcome physical limitations and improve search efficiency.
Data replication
When you have large search volumes that can’t be handled by a single node, you can distribute searches across multiple read-only copies of the index to improve search performance. By replicating the index, search queries can be processed concurrently across multiple nodes, resulting in faster response times for end-users. This makes it possible to handle large volumes of data and queries, which is critical for building a high-performing, scalable search engine.
Data replication implies keeping the primary node in sync with all of its replicas and can increase the ingestion overhead. High volumes of indexing can consume extra resources and effectively reduce search performance.
There are two main approaches to supporting data replication in Lucene:
- document replication: each replica indexes documents into index segments. A given quorum of replicas has to acknowledge the success of the insertion request for it to be considered successful by the primary.
- segment replication: only the primary ingests documents; new index segments are transferred to all replicas. This approach comes with less overhead as only the primary actually indexes the data; it guarantees point-in-time consistency.
With document-based replication, primary and replica shards are constantly communicating to stay in sync. They do this by replicating the operations performed on the primary shard to the replica shard, which means that the cost of those operations (CPU, mainly) is incurred for each replica specified. The same shards and nodes doing this work for ingest are also serving search requests, so provisioning and scaling must be done with both workloads in mind.
With segment-based replication, you can separate indexing and searching by replicating the index. This allows you to distribute indexing and searching across different nodes, which can help improve search performance and reduce the load on any one node. The approach effectively trades higher CPU consumption by the replicas for increased network consumption (transferring whole segments to replicas). By separating indexing and searching, you can ensure that your search engine remains performant and responsive, even as your indexing needs grow.
Load balancing
When your Lucene-powered search system experiences increased traffic, maintaining consistent performance becomes crucial. Some distributed search engines, such as Elasticsearch, come with their own built-in node discovery and load balancing mechanisms. These can either replace or complement traditional load balancers like Nginx or HAProxy. By intelligently distributing the workload across multiple nodes, these systems ensure that no single node is overwhelmed, resulting in a responsive and reliable search experience for users.
Through load balancing, your search infrastructure gains the ability to scale horizontally: you can dynamically add or remove nodes without disrupting service availability.
Load balancers often integrate health checks, monitoring the health of individual nodes and automatically directing traffic away from underperforming or unavailable nodes. By eliminating single points of failure and maximizing resource efficiency, load balancing contributes significantly to reliability and scalability.
Scaling Effectively
One common issue encountered in distributed systems is the time it takes for a new node to join the cluster and become fully operational. This delay can impact immediate responsiveness during peak traffic periods. To mitigate this challenge, the resources are often over-provisioned to ensure adequate capacity for traffic spikes or region failovers. However, over-provisioning can lead to unnecessary costs and waste of resources during non-peak times.
Stateless Deployment
Historically, most of Lucene deployments have been stateful. Nodes in such deployments heavily rely on local disks, and scaling often meant managing complex data transfer and node synchronization mechanisms. However, as the software ecosystem evolves towards more modular and scalable patterns, stateless is emerging as a preferred approach for deploying large-scale applications, including search.
The future is stateless.
According to Stateless — your new state of find with Elasticsearch blog.
While Lucene itself inherently deals with indexed data stored on disk, modern deployment techniques can introduce a form of statelessness in distributed search engines built on Lucene. The stateless architecture might involve moving the persistent layer from local disc to external storage solutions like Amazon S3, while the search nodes themselves are kept stateless.
Stateless containers, housing individual Lucene instances, can be rapidly spun up or down to match demand. For example, Kubernetes’ dynamic scaling and automated workload distribution can ensure that new nodes are ready to serve traffic swiftly, eliminating the need for excessive resource reservation. This approach optimizes resource utilization, reduces costs, and enables your search cluster to seamlessly handle varying workloads.
For instance, Nrtsearch: Yelp’s Fast, Scalable and Cost Effective Search Engine blog post highlights the advantages they gained from transitioning to a stateless Lucene-based search engine. The significant cost benefits stemmed primarily from the system’s capability to swiftly auto-scale in response to fluctuating user traffic.
Managed Serverless in the Cloud
The evolution of serverless architecture has reached a new level, with cloud providers offering fully managed serverless services. With these services, users no longer need to concern themselves with the underlying infrastructure, such as provisioning, scaling, and maintenance. This shift allows developers to focus solely on building search functionalities and user experiences.
Scaling Efficiently and Cost-effectively
Stateless architectures simplify auto-scaling and minimize wasted resources. This flexibility often leads to substantial cost savings for the developer. Although moving to a stateless approach can introduce challenges, such as data consistency issues, the financial and operational advantages typically outweigh the drawbacks.
Elasticsearch
Architecture
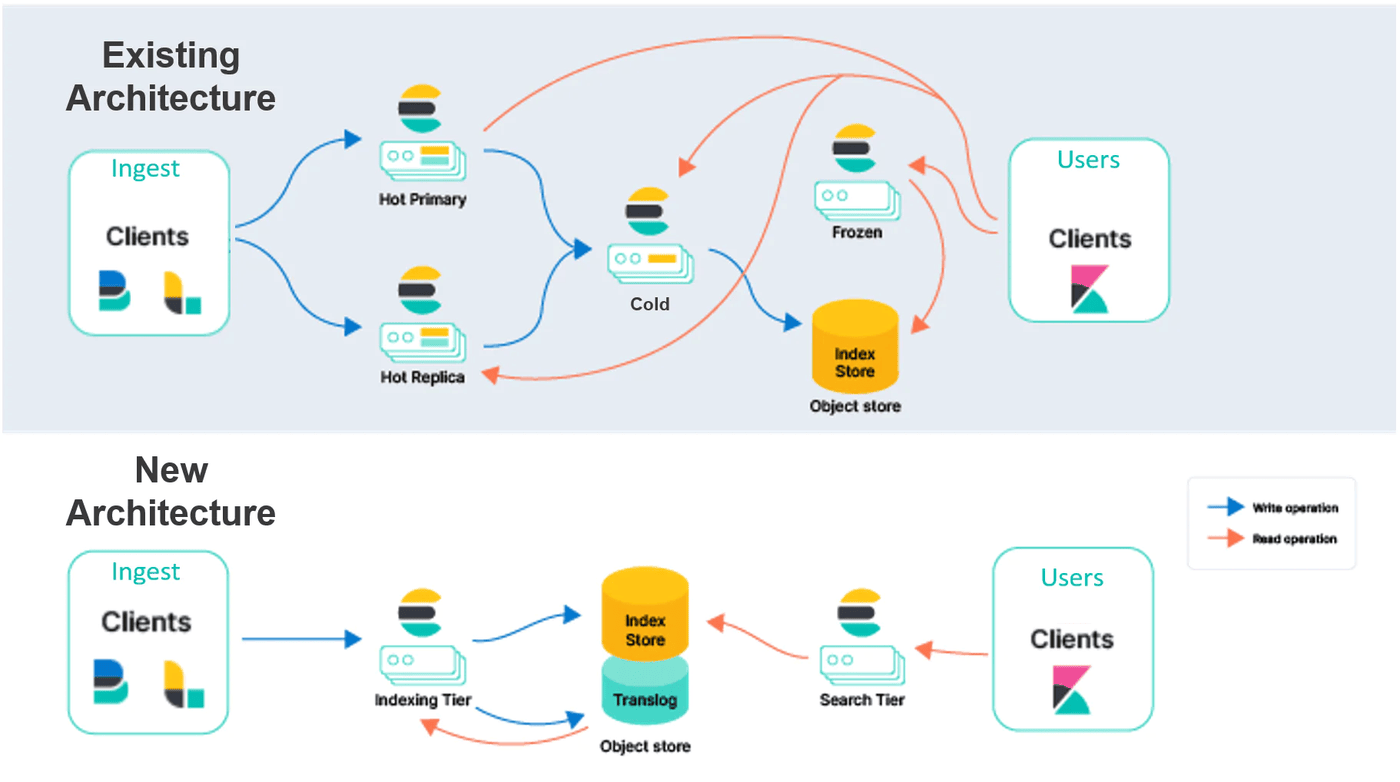
Elasticsearch runs on a stateful setup with a cluster at the core of its architecture. A cluster is a group of interconnected nodes that collectively manage and serve data. There are different types of nodes: data nodes store data, master-eligible nodes decide which node is in charge, and coordinating nodes manage search queries. Data in Elasticsearch is split into parts called shards. This makes it easy to spread data across many nodes and grow the system.
Primary shards handle data writing and manage copies called replicas. Replicas are backups; if one shard has an issue, a replica takes over. Coordinating nodes receive search requests, send them to the right shards, and calculate the answers. They don’t hold data, but they manage the flow of search requests. Data is organized into different lifecycle stages for efficient storage and access: hot for frequently accessed data, cold for less frequently accessed data, and frozen for archival data. Nodes can be specifically configured or optimized to handle data at each of these stages.
In a real-world scenario where Elasticsearch was used for a search application with heavy user traffic, I’ve witnessed several issues with that setup:
-
Document-based replication issues: In Elasticsearch, each replica indexes documents individually. This means that as you scale out with more replicas, CPU demands for indexing increase, leading to escalated costs.
-
Shard distribution issues: Elasticsearch’s automatic shard distribution can lead to “hot” nodes (overwhelmed with traffic) and “cold” nodes (underutilized). Sometimes manual intervention is needed to ensure a balanced spread of shards for optimized CPU usage.
-
Autoscaling Issues: Real-time scaling is challenging due to the need to migrate shards between nodes, causing provisioning for peak capacity. The necessity for a balanced shard distribution complicates autoscaling further, as scaling adjustments (number of new nodes joining the cluster) must align with the number of shards and replicas in each index.
Stateful and stateless
Elasticsearch is transitioning towards a stateless architecture, marking a significant departure from its traditional stateful design. In this new model, data persistence moves from local node disks to external blob storage platforms such as AWS S3. By doing so, there is no need for duplicating indexing across replica nodes, and it significantly reduces associated costs. Elasticsearch is evolving its operational structure: instead of mixing indexing and search operations on the same instances, they’ll be separated into distinct tiers. This separation means each function, indexing and searching, can scale based on its specific needs, enhancing both efficiency and performance.
Nrtsearch
While working as a software engineer at Yelp, I was part of the Ranking Platform team. We were at the core of an initiative to revamp the core search and ranking infrastructure in terms of performance and cost efficiency. This effort resulted in an open-source project - nrtsearch - which, as of 2023, is used for the majority of search and ranking use cases at Yelp. You can read more about the nrtsearch project results in the blog post from Yelp’s Engineering Blog:
Nrtsearch: Yelp’s Fast, Scalable and Cost Effective Search Engine
If you are interested in running the nrtsearch multi-node cluster locally, you can refer to the official docs or follow: Nrtsearch Tutorial - Indexing Web Content for Search with the tutorial repo.
Stateless architecture
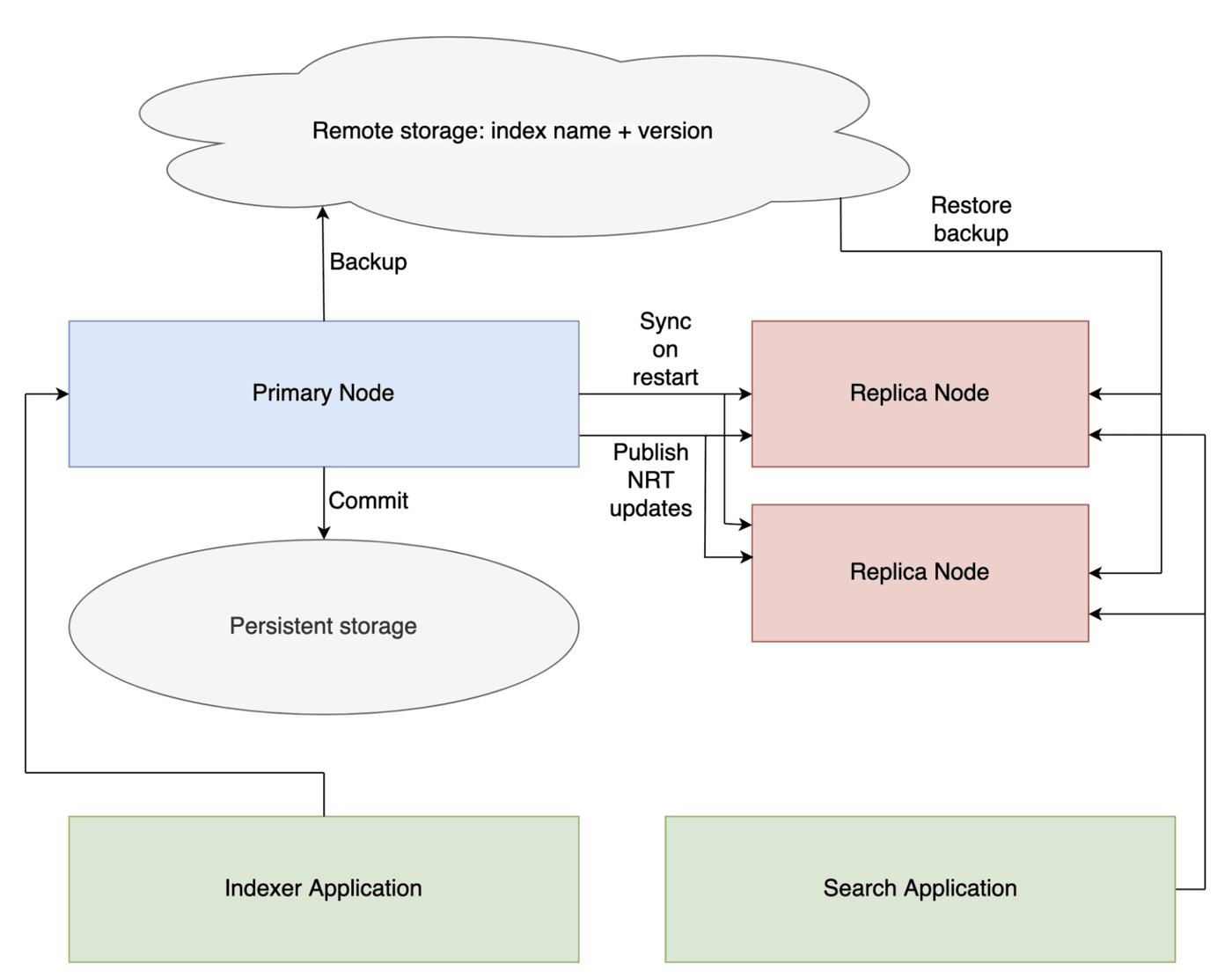
Nrtsearch is a search engine developed with specific design goals, including utilizing Lucene’s capabilities and ensuring near-real-time segment replication.
The cluster is at the core of its architecture. It consists of a single primary and replicas.
- Primary node - a single node, responsible for data indexing. It periodically publishes Lucene segment updates to replicas. Hence the name: nrtsearch - near-real time search.
- Replica nodes - one or more nodes, responsible for serving the search traffic. It receives periodic segment updates from the primary. The number of running replicas can be controlled by an auto-scaler (like HPA) to respond to changing search load.
Instead of relying on a node’s local storage, the primary copy of the index is stored externally, such as on Amazon S3. This setup ensures nodes can be swiftly rebooted without the need for local instance storage backups. The primary carries out the bulk of the work. When the primary indexes documents, it sends updates to all replicas. Replicas receive the latest segments from the primary over the network. This method effectively trades higher CPU consumption by the replicas for increased network consumption, as replicas don’t need index documents to Lucene segments on their own. However, with high networking bandwidth becoming more affordable over time, this is a feasible approach. The near-real-time segment replication offers point-in-time consistency.
Nrtsearch doesn’t include a transaction log. Clients are expected to periodically call commit to persist recent changes. If a primary node crashes, documents indexed since the last commit might be lost, but an external ETL system, like Flink, can revert to a checkpoint and resend indexing requests.
Outside of Nrtsearch, Kubernetes helps in addressing deployment challenges, such as replacing a failed primary or replica pod. Load balancing across replicas is managed on the client-side with gRPC load balancing.
In cases where data doesn’t fit onto a single primary (index size > 30GB), the index can be divided across multiple clusters. Each of these clusters has its own primary and a set of replicas. To manage such a distributed setup efficiently, a scatter-gather service needs to be used - unfortunately, it has not been open-sourced by Yelp as of 2023. This service coordinates both indexing across clusters and distributed querying. When a query is made, it’s scattered across the clusters, and each cluster processes its portion of the query. Once processed, the results are gathered and combined before being returned to the user.
Nrtsearch was built for cost-saving and easy auto-scaling. However, it’s not as user-friendly as some alternatives. Unlike Elastic’s stack with open-source tools like Kibana, nrtsearch doesn’t have as many tutorials, user docs, or publicly available scatter-gather and k8s operator service. So, while it does its main job well, you might need more setup and integration work to get everything running smoothly.